
仕事の中で、「豆板醬」という品名をSQL Serverのnvarchar列に登録しようとして文字化けするという事態が起きました。以前から「文字列の前にNを付ける、Nプリフィックスでユニコード文字を投入可能」ということは知っていたのですが、「そもそもなぜ?」について調べていなかったので、ちょっと調べた内容をメモっておきます。
Nプリフィックスでユニコード文字が登録できる直接的な理由
ざっくり言うと下記のような話のようです。なお、文字列を登録する先はnvarchar型で定義されているものとします。
- SQL ServerのSQLで扱う文字列には「定数」と「ユニコード文字列」があり、後者は「N'豆板醬'」のように、文字列の前にNを付けることで明示できる。
- 定数はSQLを解釈する過程でデータべースに定められた照合順序に対応したコードページ(文字コード表)への照合と変換が行われる。
- ユニコード文字列は、上記の照合順序に応じたコードページでの変換が行われず、そのままユニコード(UTF-16?)での文字列情報記録が行われる。
この「変換」がくせ者だったのですね。
参考URL
- Microsoft SQL Server Japan Support Team Blog / NVARCHAR/NCHAR データ型の列に格納されるデータが?になる
- https://learn.microsoft.com/ja-jp/archive/blogs/jpsql/nvarcharnchar
- Constants (Transact-SQL)/Unicode文字列
- https://learn.microsoft.com/ja-jp/sql/t-sql/data-types/constants-transact-sql?redirectedfrom=MSDN&view=sql-server-ver16#unicode-strings
変換に使われる文字コード表
SQL Serverが文字列を扱う際に変換を行う「コードページ」こと文字コード表は、照合順序によって規定されているようです。
上記のブログに、実際に利用されるコードページを調べた結果が記載されていたので参考にさせてもらいました。どうやら照合順序の名称が「Japanse_****_UTF8」になっているものは、コードページ65001(UTF-8)を用い、それ以外はCP932(Windows3.1時代からのShift-JISに近い文字コード表)を使っているようです。実際に試してはいませんが、恐らくこのUTF-8対応の照合順序を指定していれば、Nプリフィックス無しでもUTF-8文字列がスッと格納されるのではないかとおもいます。
豆板醬が化けた理由
では、文字列「豆板醬」が化けた理由について。この「醬」という文字は訓読みだと「ひしお」、いわゆる醤油の「しょう」と同じ意味の別の字体の漢字です。いつもの「Unisearcher」で文字を検索してみると下図のような情報が出てきます。
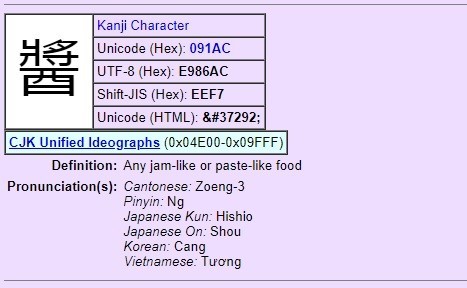
- UTF-8 …… E986AC
- Shift-JIS: …… EEF7
Shift-JISの文字コードを持っているんですよね。ですがCP932では化けました。ということは、CP932には含まれない、新しいShift-JISの文字なのかもしれません。特定の文字が「どのSJISに含まれるか」を調べる方法が分からなかったので、いくつか検索した結果、下記サイトの文字コード表でSJISの種類毎の表があり、その中の「Shift_JIS2004」に「醬」の文字がEEF7として掲載されているのを見つけました。
どうやら「Shift_JIS-2004(JIS X 0213:2004)」と呼ばれるタイプのShift-JIS文字コードのようです。確かに「Shift-JIS」としてのコードはあるのですが、CP932には含まれないのでSQL Serverは内部処理で文字化けを起こしたのですね。

調べ切れていないこと
とりあえず文字化けした原因と回避方法、その方法で対処できる仕組みについては把握できたと思います(今まできちんと調べてなかったのが恥ずかしい)。ただ、下記の点はまだよく分かっていないので、Quoraとかも使いながらできれば把握しておきたいと思います。
- そもそもなぜ、文字定数を受け付けた際に照合順序に応じた変換処理を行うのか?
- (調べる過程で出てきた疑問)照合順序を明示的にSQL中で指定するとvarchar列にUTF-8コードで文字列を入れることもできるらしい……そもそもSQL Serverの文字列型と、そのバイナリーデータとしての実態の関係はどうなっているのか?型ってなんだ?
後者は下記のブログを読んでいて浮かんだ疑問です。